Σχεδιασμός και υλοποίηση
Θεσμικό Πλαίσιο
Το νέο λογισμικό αναγνωσιμότητας ελληνικών κειμένων αναπτύχθηκε στο πλαίσιο του συγχρηματοδοτούμενου προγράμματος «Πράξη 54: Πιστοποίηση ελληνομάθειας: υποστήριξη και ποιοτική ανάδειξη της διδασκαλίας/εκμάθησης της ελληνικής ως ξένης/δεύτερης γλώσσας» του Κέντρου Ελληνικής Γλώσσας και συνιστά επανασχεδιασμό του παλαιότερου ανάλογου λογισμικού “grval 1.1” της «Πύλης για την Ελληνική Γλώσσα».
Σκοπός
Το νέο αυτό λογισμικό αναπτύχθηκε με σκοπό να αποτελέσει:
- α) μια πιο αξιόπιστη και εγκυρότερη λύση για την αξιολόγηση της δυσκολίας των ελληνικών κειμένων που χρησιμοποιούνται στην ανάπτυξη των εξεταστικών θεμάτων για τα διάφορα επίπεδα της πιστοποίησης ελληνομάθειας και
- β) ένα βοήθημα για τους διδάσκοντες την ελληνική ως ξένη/δεύτερη γλώσσα στην επιλογή των κατάλληλων κειμένων για το επίπεδο ελληνομάθειας των μαθητών τους.
Υλοποίηση
Η υλοποίηση του νέου λογισμικού αναγνωσιμότητας διενεργήθηκε σε τρεις φάσεις:
- Προσδιορισμός των κειμενικών παραμέτρων της αναγνωσιμότητας από ειδική ερευνητική ομάδα γλωσσολόγων (βλ. ενότητα «Ομάδα εργασίας»). Τελικά προκρίθηκαν 16 διαφορετικές παράμετροι, στις οποίες περιλαμβάνονται: α) παράμετροι που χρησιμοποιούν μερικοί από τους πιο διαδεδομένους τύπους υπολογισμού του βαθμού αναγνωσιμότητας διεθνώς, όπως οι FleschReadingEase, Flesch-KincaidGradeLevel, SMOG και FleschFogIndex, τις οποίες χρησιμοποιούσε και το παλαιότερο λογισμικό, και β) επιπλέον παράμετροι, βάσει πρόσφατης σχετικής βιβλιογραφίας ειδικά για την ελληνική γλώσσα (βλ. ενότητα «Βιβλιογραφία»).
- Ανάπτυξη από ειδικό στατιστικολόγο νέου μαθηματικού προτύπου υπολογισμού της αναγνωσιμότητας με βάση στατιστική μοντελοποίηση πολυωνυμικής λογιστικής παλινδρόμησης (multinomial logistic regression) και την αξιοποίηση σχετιζόμενων στατιστικών κριτηρίων και παραμέτρων. Από πλευράς δεδομένων η στατιστική μοντελοποίηση στηρίχτηκε σε 586 κείμενα εκπαίδευσης και 191 ελέγχου. Αυτά τα κείμενα ήταν ήδη διαβαθμισμένα ανά επίπεδο ελληνομάθειας και ήδη χρησιμοποιημένα από συνεργάτες της πιστοποίησης ελληνομάθειας σε εξεταστικά θέματα κατανόησης γραπτού και προφορικού λόγου. Η διαδικασία που ακολουθήθηκε ήταν η εξής:
- α) επιλογή και μοντελοποίηση 13 κειμενικών μεταβλητών ώστε να επιτευχθεί η βέλτιστη διακριτική ισχύς, σε συνδυασμό με την ευστάθεια του μοντέλου με βάση στατιστικά κριτήρια
- β) δημιουργία και ενσωμάτωση στον τελικό μαθηματικό τύπο του μοντέλου υπολογισμού αναγνωσιμότητας, επιπλέον μεταβλητής σχετιζόμενης με την έκταση του κειμένου προκειμένου να ενισχυθεί περαιτέρω η διακριτική ισχύς του μοντέλου (βλ. 13η παράμετρος ενότητας «Διευκρινίσεις για τις κειμενικές παραμέτρους»).
- Ανάπτυξη σχετικής ιστοσελίδας με ενσωματωμένο τον νέο τύπο υπολογισμού αναγνωσιμότητας προς χρήση του κοινού.
Το αποτέλεσμα
Ο χρήστης έχει πια στη διάθεσή του ένα λογισμικό αναγνωσιμότητας το οποίο:
- α) είναι «εκπαιδευμένο» βάσει σώματος αυθεντικών ελληνικών κειμένων, διαβαθμισμένων εκ των προτέρων και στα έξι ισχύοντα επίπεδα ελληνομάθειας με αυστηρά κριτήρια,
- β) χρησιμοποιεί περισσότερες παραμέτρους με αυξημένη διακριτική ισχύ μεταξύ των επιπέδων ελληνομάθειας,
- γ) δίνει εκτίμηση για την απευθείας αντιστοίχιση βαθμού αναγνωσιμότητας – επιπέδου ελληνομάθειας και
- δ) υπολογίζει τις πιθανότητες που αντιστοιχούν σε όλα τα επίπεδα ελληνομάθειας, ώστε ο διδάσκων ή ο ερευνητής να εστιάσει σε ορισμένες από αυτές (συνήθως 2) με τις μεγαλύτερες τιμές.
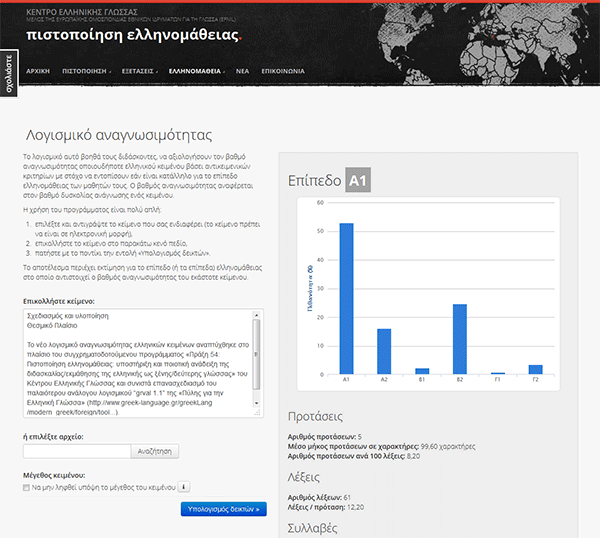
Η τελική μορφή που παίρνει το νέο λογισμικό αναγνωσιμότητας μετά την εισαγωγή του προς εξέταση κειμένου είναι η εξής:
Τελευταία ανανέωση: 31/03/2014 21:47